REST architecture and URLs
Learning Goals
By the end of this lesson, you will:
- Know how to talk about the various parts of a url
- Understand the fundamentals of REST API design
- Talk to some high level differences between REST, SOAP and GraphQL
- Gain familiarity with the concept of API versioning
Vocab
- API - Application programming interface
- CRUD - Create, Read, Update, Destroy
- REST - representational state transfer
- API versioning - the practice of managing changes to an API and ensuring that these changes are made without disrupting clients
Warmup
Take some time to explore these one of the following APIs:
Explore the documentation and utilize the dev tools to answer the following questions in your journal:
- What are the available endpoints and their functionalities?
- What kind of data does the API provide?
- What are the potential use cases for the API?
The anatomy of a URL
Our applications will request HTML documents, CSS files, images, and data. The way each of these requests are made is quite different:
- Typing a URL like
https://www.turing.eduinto the browser makes a request for an HTML document - Including a link tag to request an external stylesheet:
<link href="https://www.turing.edu/css/styles.css" /> - Adding an image element to display a logo:
<img src="https://www.turing.edu/images/logo.png" />. - Making a fetch request to retrieve data:
fetch('https://www.turing.edu/api/v1/users')
While the syntax for each of these requests looks significantly different, they all share one thing in common: Every request we make to an HTTP Server requires a URL.
In the first 3 requests we’re fetching a static asset, whereas the last one is requesting data from an api endpoint.
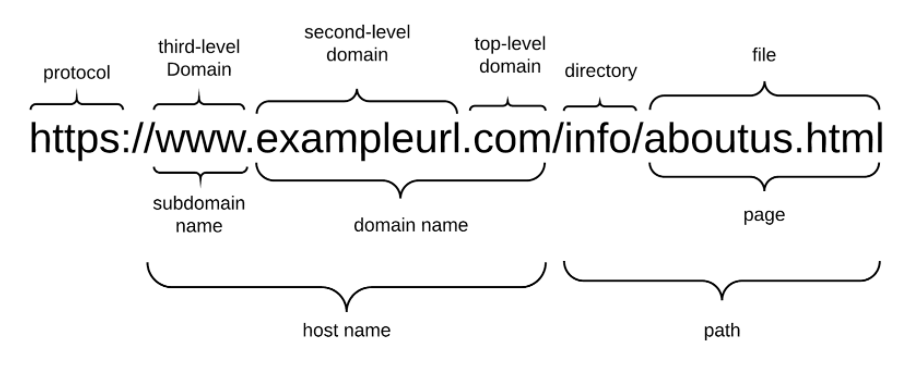
When fetching data, you’ll often hear the URL referred to as an “endpoint”. These endpoints (e.g. https://www.turing.edu/api/v1/users) are created by the back-end developers on a team to help the front-end developers access and interact with application data. Just like the front-end, there are many frameworks and libraries that back-end developers will use to to set up a proper HTTP Server with all the necessary endpoints.
Endpoints have two main components:
- HTTP method
- The url (sometimes shortened to only the path)
Therefore if you were to write documentation for the example endpoint above, you could do so in a few ways:
- GET
https://www.turing.edu/api/v1/users- the whole shabang - GET
/api/v1/users- just the path (assuming we know the domain) - GET
users- specific part of the path that changes (assuming we know the base url including the api structure info)
Note on HTTP
It is simply the protocol for transmitting documents across the internet. There are a bunch more (SSH, POP,FTP…) but we will focus on HTTP since it’s primarily used for communication between web browsers and web servers. Hypertext is just structured text that uses links (hyperlinks) between other nodes of structured text. The key to HTTP is that it is stateless, the server doesn’t save data between requests.
Some Introspection
Think back to the API endpoints you explored in the warmup. How were they structured? Did you have to use different HTTP methods? Write down some URLs that you had to use to make API requests.
RESTful API design
During your time as a frontend developer, you’ve already been hitting RESTful endpoints. What is REST exactly?
REST stands for representational state transfer. This means that web resources communicate using a set of stateless, uniform operations.
RESTful architecture includes sending HTTP methods to a URL to get back information from a request. The primary methods, which are often called CRUD methods (Create, Read, Update, and Destroy) are as follows:
- GET - Retrieve resource information identified by the request
- POST - Create a new resource
- PUT - Fully update a specific resource in its entirety
- PATCH - Update only a portion of a specific resource
- DELETE - Destroy an entire specific resource by the request
Typically there are only 2 paths for a given resource when it comes to RESTFUL endpoints. For example, if we have an ideabox app. Those two paths would be:
/ideas- used to generically identify the type of resource. Because we may not have an id yet or we want a collection./ideas/:id- used to identify a specific resource of that type.
That’s a lot of words, at a high level, REST is really just a pattern that matches CRUD operations to endpoints.
What RESTful api endpoint have you used in the past? How do you know they’re RESTful?
Activity time!
With a partner, design an api that implements CRUD for sharks or puppies (based on the app we worked on yesterday). For each type of request - GET, POST, and DELETE - answer these questions:
- What endpoints will you need? Write down the URLs.
- What information do you need in the request?
- What will you send back in the response? (i.e. What data? What response status?)
HINT: Consider organizing your work in a table, like this one. If you’d like, you can use this template to get started.
Some alternatives
REST API is the only design paradigm when it comes to making APIs, so let’s explore some alternatives:
Breakout Activity
You and two others will be comparing and contrasting the different types of API designs.
- The oldest member of your group will be presenting on SOAP APIs.
- The youngest member of your group will be presenting on GraphQL.
- The middle member of your group will be presenting on REST APIs.
These presentations should be short and concise, there’s no need to go beyond surface level here. The purpose of this activity is to highlight a few key differences between API designs so you have some ground to start on if presented with an API outside of REST protocol.
Each short presentation should include:
- Data representation (how is data is formatted and utilized in the API)
- Pros & cons of each design
- Unique use cases or considerations
API Versioning
API versioning is a crucial aspect of developing and maintaining APIs. It allows developers to introduce changes and enhancements to their APIs while ensuring backward compatibility. It is commonly implemented by including version numbers in the URL.
Consider this scenario
Your team is responsible for maintaining an API endpoint that provides product information: https://api.example.com/v1/products. Thousands of businesses use your endpoint for looking up your product information.
One day, your product manager sends your team a ticket that updates your endpoint to change the shape of your response (i.e. the JSON schema changes: more properties are added, and the keys of some properties are changed).
As you finish work on this ticket, a senior developer updates the endpoint that serves this data to https://api.example.com/v2/products.
As the work is submitted and the API endpoint goes live, your product manager asks you this final question:
- Why might it be important to maintain both v1 and v2 endpoints?
Why is API versioning important?
API versioning is a crucial aspect of developing and maintaining APIs. It allows developers to introduce changes and enhancements to their APIs while ensuring backward compatibility.
- Backward Compatibility: API versioning ensures that existing client applications and integrations continue to function correctly even when changes are made to the API. It allows developers to introduce updates and improvements without breaking the functionality of older client versions.
- Smooth Transition: Versioning enables a smooth transition for clients and users when significant changes or new features are introduced. It provides a clear separation between different API versions, allowing clients to migrate to newer versions at their own pace.
- Flexibility: API versioning allows developers to iterate and evolve their APIs over time. It provides the flexibility to make enhancements, fix bugs, and address scalability or security concerns without disrupting existing API consumers.
- Clear Documentation: By incorporating version numbers in the URL, API versioning simplifies the documentation process. It allows for clear and concise documentation of each version’s features, changes, and migration instructions, aiding developers and users in understanding and utilizing the API effectively.
Interview prep
In an interview, you might be asked these kinds of questions concerning APIs:
- What are the different parts of an API URL, and why are they important?
- What does CRUD stand for and how does it relate to representational state transfer?
- What are some advantages/disadvantages of REST/SOAP/GraphQL?
- Why is versioning your API important?